

Introducción
El Procesamiento del Lenguaje Natural (PLN) es una rama de la Inteligencia Artificial (IA) que combina lingüística computacional, estadística, aprendizaje automático y redes neuronales profundas con el propósito de permitir que las máquinas comprendan, interpreten, generen y manipulen el lenguaje humano.
Hoy, el PLN está en el centro de casi todas las aplicaciones de IA que usamos: desde los asistentes virtuales como Siri, Alexa o Google Assistant, hasta herramientas de productividad como ChatGPT, Claude o Gemini. Entender sus fundamentos técnicos es clave para desarrollar proyectos, implementar soluciones en organizaciones y tomar decisiones informadas sobre su uso.
Esta guía te llevará desde los principios lingüísticos y algorítmicos hasta los modelos modernos como Transformers y GPT, explorando casos de uso prácticos y retos actuales.
1. Fundamentos lingüísticos del PLN
Antes de entrar en algoritmos y modelos, es importante recordar que el PLN nace de la intersección entre la lingüística y la computación. El lenguaje humano tiene varios niveles de análisis:
- Fonología y fonética: estudio de los sonidos del habla. Ejemplo: convertir voz a texto con reconocimiento automático de voz (ASR).
- Morfología: análisis de la estructura interna de las palabras. Ejemplo: “correr”, “corriendo”, “corrí”.
- Sintaxis: reglas que gobiernan la estructura de frases. Ejemplo: “El perro persigue al gato” vs. “Persigue perro gato”.
- Semántica: significado literal de las palabras y frases.
- Pragmática: significado contextual o intencional. Ejemplo: “¿Puedes abrir la ventana?” se interpreta como una petición, no como una pregunta sobre capacidad.
- Discurso: cómo se relacionan las oraciones entre sí en un texto o conversación.
👉 El PLN busca modelar, en distintos niveles, cómo procesar estos aspectos del lenguaje humano de manera computacional.
2. Evolución histórica del PLN
2.1. Primera etapa: Reglas y gramáticas (1950–1980)
- Uso de gramáticas formales (Chomsky, Backus-Naur).
- Sistemas expertos basados en reglas lingüísticas.
- Limitación: poco escalables y difíciles de mantener.
2.2. Segunda etapa: Estadística y aprendizaje automático (1980–2010)
- Introducción de modelos probabilísticos: N-gramas, cadenas de Markov ocultas (HMM), modelos de máxima entropía.
- Aplicaciones: traducción automática estadística (Moses), etiquetado de partes del discurso, modelos de lenguaje simples.
2.3. Tercera etapa: Deep Learning y redes neuronales (2010–presente)
- Redes neuronales recurrentes (RNN, LSTM, GRU).
- Modelos de word embeddings: Word2Vec, GloVe, FastText.
- Gran salto con los Transformers (2017) y modelos como BERT, GPT, T5.
- Hoy: modelos fundacionales (GPT-4, Claude 3, Gemini, LLaMA) capaces de trabajar en múltiples modalidades (texto, imagen, audio, video).
3. Componentes técnicos del PLN
A continuación, revisemos los componentes técnicos del Procesamiento de Lenguaje Natural.
3.1. Representación de texto
La computadora no entiende palabras como tal; necesita convertirlas en vectores numéricos.
- Bag of Words (BoW): representación basada en frecuencias. Limitada porque ignora el orden.
- TF-IDF: pondera términos según su relevancia en un documento frente a un corpus.
- Word Embeddings: vectores densos que capturan relaciones semánticas. Ejemplo: “rey – hombre + mujer ≈ reina”.
- Embeddings contextuales: modelos como BERT generan vectores diferentes para una palabra según su contexto.
3.2. Modelos de lenguaje
Un modelo de lenguaje predice la probabilidad de una secuencia de palabras.
- Ejemplo clásico: en español, “buenos ___” → el modelo predice con alta probabilidad “días”.
- Algoritmos: n-gramas, redes neuronales recurrentes, transformers.
3.3. Preprocesamiento de texto
Aunque hoy los modelos grandes (como GPT, BERT o Claude) realizan gran parte de este trabajo de forma automática, comprender los pasos del pipeline clásico permite entender cómo los datos textuales se transforman en insumos procesables para los algoritmos. Los pasos son:
A. Tokenización
La tokenización consiste en dividir un texto en unidades básicas llamadas tokens.
- Tokens: pueden ser palabras, subpalabras o incluso caracteres.
- Ejemplo simple:
Texto: “El perro ladra fuerte”
Tokens (palabras): [“El”, “perro”, “ladra”, “fuerte”]
Existen diferentes enfoques:
- Por palabras: separación por espacios y signos de puntuación.
- Por caracteres: cada letra o símbolo se considera un token. Útil en idiomas sin separación clara (como el chino).
- Por subpalabras: técnica usada en Transformers modernos (BERT, GPT). Ejemplo: la palabra “jugábamos” se descompone en [“jug”, “ábamos”], lo que permite manejar palabras desconocidas o muy raras.
Importancia: la tokenización convierte un flujo continuo de texto en piezas discretas que la computadora puede mapear a vectores numéricos.
B. Normalización
La normalización busca unificar el formato del texto para evitar variaciones innecesarias.
Acciones comunes:
- Convertir todo a minúsculas: “Hola” y “hola” se procesan igual.
- Eliminar acentos o diacríticos: “acción” → “accion”.
- Quitar caracteres especiales: emojis, símbolos o signos redundantes.
- Sustituir contracciones: “del” → “de el”.
- Manejo de puntuación: algunas aplicaciones eliminan comas y puntos, otras los mantienen para análisis sintáctico.
Importancia: si no normalizas, el sistema podría tratar “Casa” y “casa” como dos palabras diferentes, multiplicando innecesariamente el vocabulario.
C. Eliminación de stopwords
Las stopwords son palabras muy frecuentes en un idioma, como artículos, preposiciones o conjunciones.
- Ejemplo en español: “el”, “la”, “de”, “que”.
- Ejemplo en inglés: “the”, “of”, “and”, “is”.
Al eliminarlas, se reduce el ruido y el tamaño de los datos, concentrándose en los términos relevantes.
- Ejemplo:
Texto: “El perro ladra fuerte en la noche”
Sin stopwords: [“perro”, “ladra”, “fuerte”, “noche”]
Importancia: en tareas como clasificación de documentos o análisis de sentimientos, estas palabras suelen aportar poca información semántica. Sin embargo, en aplicaciones más avanzadas (traducción automática, modelos neuronales modernos), muchas veces se mantienen porque también tienen valor sintáctico.
D. Lematización
La lematización reduce cada palabra a su forma base o “lema”, considerando reglas lingüísticas y contextuales.
- Ejemplo:
- “corriendo” → “correr”
- “jugadores” → “jugador”
- “mejores” → “mejor”
A diferencia del stemming, la lematización respeta la morfología y la gramática. Para lograrlo, requiere diccionarios y análisis lingüístico.
Importancia: mejora la precisión al comparar palabras, porque “correr”, “corrió” y “corriendo” se reconocen como la misma acción.
E. Stemming
El stemming consiste en cortar sufijos o prefijos para reducir la palabra a su raíz.
- No siempre respeta reglas gramaticales.
- Ejemplo:
- “jugando” → “jug”
- “jugador” → “jug”
- “jugaría” → “jug”
Esto produce raíces que pueden no ser palabras reales, pero sirven como representación común.
Importancia: más rápido y sencillo que la lematización. Útil cuando se prioriza velocidad sobre precisión, como en motores de búsqueda o análisis de grandes volúmenes de texto.
Comparación rápida: Lematización vs. Stemming
| Aspecto | Lematización | Stemming |
| Método | Basado en reglas gramaticales y diccionarios | Basado en recortes de sufijos/prefijos |
| Resultado | Palabras válidas (ej. “corriendo” → “correr”) | Raíces truncadas (ej. “corriendo” → “corr”) |
| Precisión | Alta | Media/Baja |
| Velocidad | Más lenta | Más rápida |
| Uso típico | PLN avanzado (traducción, NER, análisis sintáctico) | Motores de búsqueda, indexación de textos |
Ejemplo completo de pipeline
Texto original:
"Los niños estaban jugando alegremente en el parque."
- Tokenización: [“Los”, “niños”, “estaban”, “jugando”, “alegremente”, “en”, “el”, “parque”]
- Normalización: [“los”, “niños”, “estaban”, “jugando”, “alegremente”, “en”, “el”, “parque”]
- Stopwords eliminadas: [“niños”, “jugando”, “alegremente”, “parque”]
- Lematización: [“niño”, “jugar”, “alegremente”, “parque”]
- Stemming: [“niñ”, “jug”, “alegr”, “parqu”]
3.4. Algoritmos clave
Un algoritmo es un conjunto de pasos bien definidos que permiten resolver un problema o realizar una tarea.
- En términos simples: es una receta que indica cómo transformar una entrada en una salida.
- Ejemplo cotidiano: una receta de cocina es un algoritmo donde los ingredientes (entrada) se transforman en un platillo (salida).
- Ejemplo computacional: un algoritmo de ordenamiento toma una lista de números desordenados [5, 1, 3] y devuelve la lista ordenada [1, 3, 5].
En PLN, los algoritmos se usan para procesar y analizar texto, desde clasificar un correo como spam o no spam, hasta traducir un párrafo completo de un idioma a otro.
3.5 Algoritmos y técnicas comunes en PLN
A. Clasificación de texto
La clasificación consiste en asignar categorías predefinidas a fragmentos de texto.
- Naive Bayes: un algoritmo probabilístico basado en la teoría de Bayes. Se usa mucho en detección de spam.
- Ejemplo: un correo con las palabras “ganaste”, “premio” y “dinero” tiene alta probabilidad de ser spam.
- SVM (Máquinas de Vectores de Soporte): separa clases mediante un hiperplano en un espacio vectorial. Muy eficiente en problemas de clasificación binaria.
- Ejemplo: clasificar reseñas de productos como “positivas” o “negativas”.
- Transformers: modelos más modernos (como BERT o RoBERTa) que entienden contexto completo.
- Ejemplo: clasificación multinivel en artículos médicos (diagnóstico, tratamiento, prevención).
Aplicación práctica: motores de búsqueda que clasifican páginas según relevancia, o aplicaciones que filtran automáticamente correos de trabajo vs. personales.
B. Análisis de sentimientos
Este algoritmo detecta la polaridad emocional en un texto: positiva, negativa o neutra. Algunos sistemas más avanzados detectan emociones específicas (alegría, enojo, tristeza, sorpresa).
- Ejemplo en negocios: una empresa analiza miles de tweets para saber si la opinión sobre un nuevo producto es favorable o no.
- Ejemplo en política: medir la reacción de la población a un discurso presidencial.
- Ejemplo en ministerio: evaluar los comentarios en redes sociales de una iglesia para conocer el impacto emocional de una campaña evangelística.
Importancia: convierte opiniones cualitativas en datos cuantitativos, lo cual ayuda a tomar decisiones estratégicas.
C. Extracción de información (NER: Named Entity Recognition)
La extracción de información busca identificar y clasificar fragmentos de texto que corresponden a entidades específicas como personas, organizaciones, fechas, lugares, porcentajes o cantidades.
- Ejemplo:
Texto: “Apple anunció el lanzamiento del iPhone en septiembre de 2025 en California”- Apple → Organización
- iPhone → Producto
- septiembre de 2025 → Fecha
- California → Lugar
Aplicación práctica:
- Motores de búsqueda (Google resalta entidades clave).
- Sistemas financieros (extraer nombres de empresas de reportes).
- Aplicaciones legales (extraer nombres de personas y fechas en contratos).
D. Traducción automática
La traducción automática busca convertir texto de un idioma a otro.
- Primera generación: basada en reglas lingüísticas. Cada idioma tenía gramáticas codificadas manualmente. Limitación: difícil de mantener, baja escalabilidad.
- Segunda generación: traducción estadística (SMT). Basada en grandes corpus bilingües y probabilidades. Ejemplo: Google Translate antes de 2016.
- Tercera generación: traducción neuronal (NMT). Modelos basados en redes neuronales recurrentes primero, y después en Transformers. Hoy, DeepL o Google Translate logran traducciones fluidas, incluso con contexto cultural.
Ejemplo práctico:
Texto en inglés: “I’m feeling blue”
- Traducción literal: “Me estoy sintiendo azul” (incorrecta).
- Traducción neuronal contextual: “Me siento triste” (correcta).
E. Generación de texto
La generación automática de texto consiste en producir secuencias coherentes a partir de un prompt o instrucción inicial.
- Modelos autoregresivos: como GPT (Generative Pre-trained Transformer), generan palabra por palabra prediciendo la más probable siguiente.
- Ejemplo:
Prompt: “Escribe una introducción a un libro sobre liderazgo cristiano”
GPT puede producir: “El liderazgo cristiano no es simplemente dirigir personas, sino inspirarlas a través del servicio y la fe…”
Aplicaciones prácticas:
- Asistentes de redacción (copys publicitarios, informes, posts en redes).
- Creación de guiones para pódcast o sermones.
- Generación de código fuente en programación.
3.6 Relación entre los algoritmos
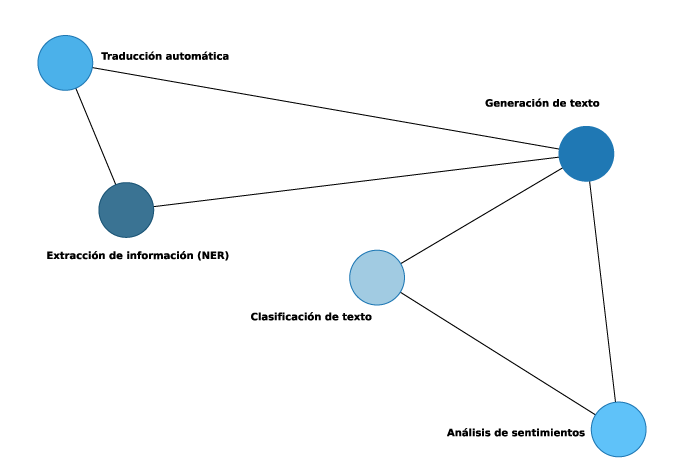
- Clasificación y análisis de sentimientos suelen usarse juntos: un sistema puede clasificar un tweet como “opinión de cliente” y luego determinar si es positiva o negativa.
- NER y traducción automática pueden integrarse: primero se extraen entidades y después se asegura que se traduzcan correctamente en otro idioma.
- Generación de texto se alimenta de todas las técnicas anteriores: necesita clasificar contextos, entender sentimientos y reconocer entidades para producir respuestas más naturales.
4. Arquitectura moderna: Transformers
El paper “Attention is All You Need” (Vaswani et al., 2017) revolucionó el PLN al introducir la arquitectura de Transformers, que reemplazó las redes recurrentes.
4.1. Principio clave: Atención
El mecanismo de self-attention permite que el modelo evalúe la importancia de cada palabra en relación con las demás.
- Ejemplo: en “El gato que estaba en el tejado se durmió”, la palabra “que” depende de “gato”. El modelo puede captarlo mejor que una RNN.
4.2. Componentes principales
- Encoder: usado en BERT para tareas de comprensión.
- Decoder: usado en GPT para tareas de generación.
- Embeddings posicionales: añaden información sobre el orden de las palabras.
4.3. Modelos derivados
- BERT: comprensión de texto (clasificación, preguntas y respuestas).
- GPT: generación de texto.
- T5: convierte cualquier tarea en un problema de “texto a texto”.
- Multimodales: procesan texto + imágenes + audio (ej. Gemini, GPT-4o).
5. Ciclo de trabajo en PLN
Un sistema típico de PLN pasa por estas fases:
- Entrada: texto, voz o documento.
- Preprocesamiento: limpieza y normalización.
- Representación: embeddings.
- Modelo: clasificación, traducción, generación, etc.
- Postprocesamiento: ajustes de formato, filtros.
- Salida: respuesta en texto, voz o acción.
6. Aplicaciones avanzadas del PLN
El PLN está presente en múltiples sectores. Vamos a profundizar en los más importantes:
6.1. Chatbots y atención al cliente
- Uso de modelos de intención + NER.
- Integración con sistemas CRM (Salesforce, Zendesk).
- Beneficio: reducción de costos operativos y respuesta inmediata.
6.2. Educación y formación
- Tutores virtuales adaptativos.
- Generación automática de exámenes y rúbricas.
- Plataformas como Duolingo AI adaptan la enseñanza al ritmo del estudiante.
6.3. Salud
- Procesamiento de historias clínicas electrónicas.
- Chatbots de triage médico.
- Análisis de literatura científica para descubrimiento de fármacos.
6.4. Negocios y productividad
- Resúmenes automáticos de reuniones en Zoom o Teams.
- Redacción automática de contratos y correos.
- Herramientas de análisis de tendencias en redes sociales.
6.5. Creatividad
- Generación de guiones, libros y artículos.
- Herramientas de copywriting inteligente.
- Apoyo en producción audiovisual: subtítulos, doblajes, sinopsis.
6.6. Traducción automática
- De Google Translate estadístico → a DeepL con redes neuronales.
- Hoy: traducción con contexto cultural y estilo.
6.7. Seguridad y ciberinteligencia
- Detección de fake news.
- Identificación de patrones sospechosos en correos (phishing).
- Monitorización de redes sociales para análisis político o de seguridad.
7. Retos del PLN
Aunque los modelos son impresionantes, existen limitaciones:
- Alucinaciones: respuestas falsas pero plausibles.
- Sesgos: reproducen prejuicios presentes en los datos de entrenamiento.
- Privacidad: uso de datos sensibles.
- Costo computacional: entrenar modelos gigantes (ej. GPT-4) requiere recursos inmensos.
- Lenguas minoritarias: menos recursos para idiomas fuera del inglés.
8. Futuro del PLN
El futuro apunta a tres grandes áreas:
- Modelos multimodales: integración fluida de texto, imagen, audio y video.
- PLN especializado: modelos entrenados en dominios específicos (salud, derecho, teología).
- PLN embebido: aplicaciones ligeras en dispositivos móviles sin depender de la nube.
Además, veremos más regulación para abordar ética, privacidad y sesgos.
9. Casos prácticos en Inteliagentes
En el marco de nuestros cursos, el PLN se aplica en:
- Creación de devocionales personalizados con IA.
- Automatización de calendarios de contenido.
- Análisis de datos de campañas de marketing.
- Generación de agentes de IA que conversan con audiencias en sitios web.
Conclusión
El Procesamiento del Lenguaje Natural es uno de los campos más dinámicos de la Inteligencia Artificial. Conocer sus fundamentos técnicos —desde la lingüística hasta los Transformers— permite a líderes, emprendedores y estudiantes usar la IA de forma más efectiva y responsable.
La clave no está en reemplazar al ser humano, sino en potenciar su creatividad, productividad y capacidad de comunicación.
En Inteliagentes, seguimos explorando estos avances con una visión práctica: que cada participante pueda llevar el PLN a sus proyectos reales, desde una pequeña empresa hasta un ministerio, desde un curso online hasta una estrategia de marketing digital.